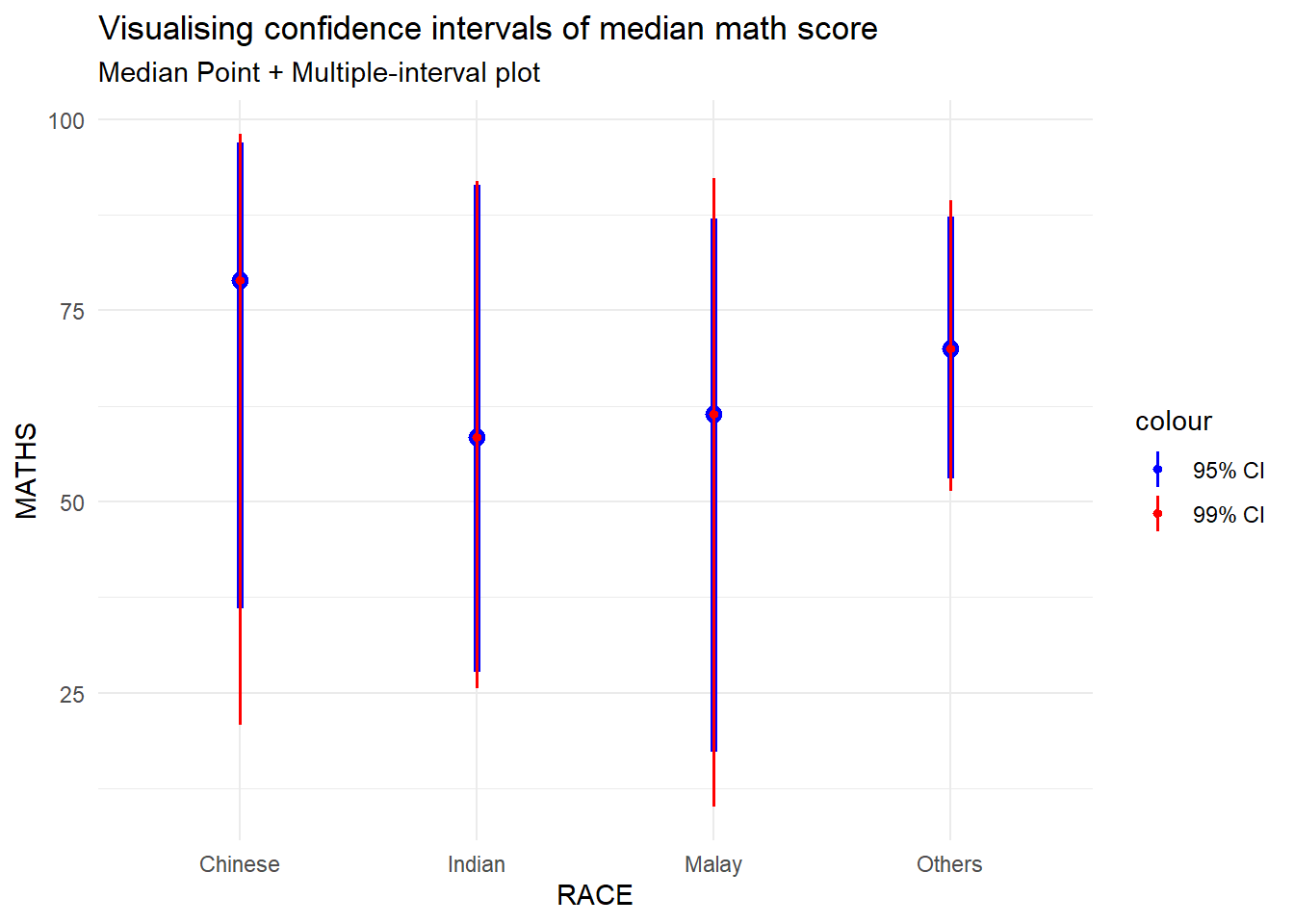
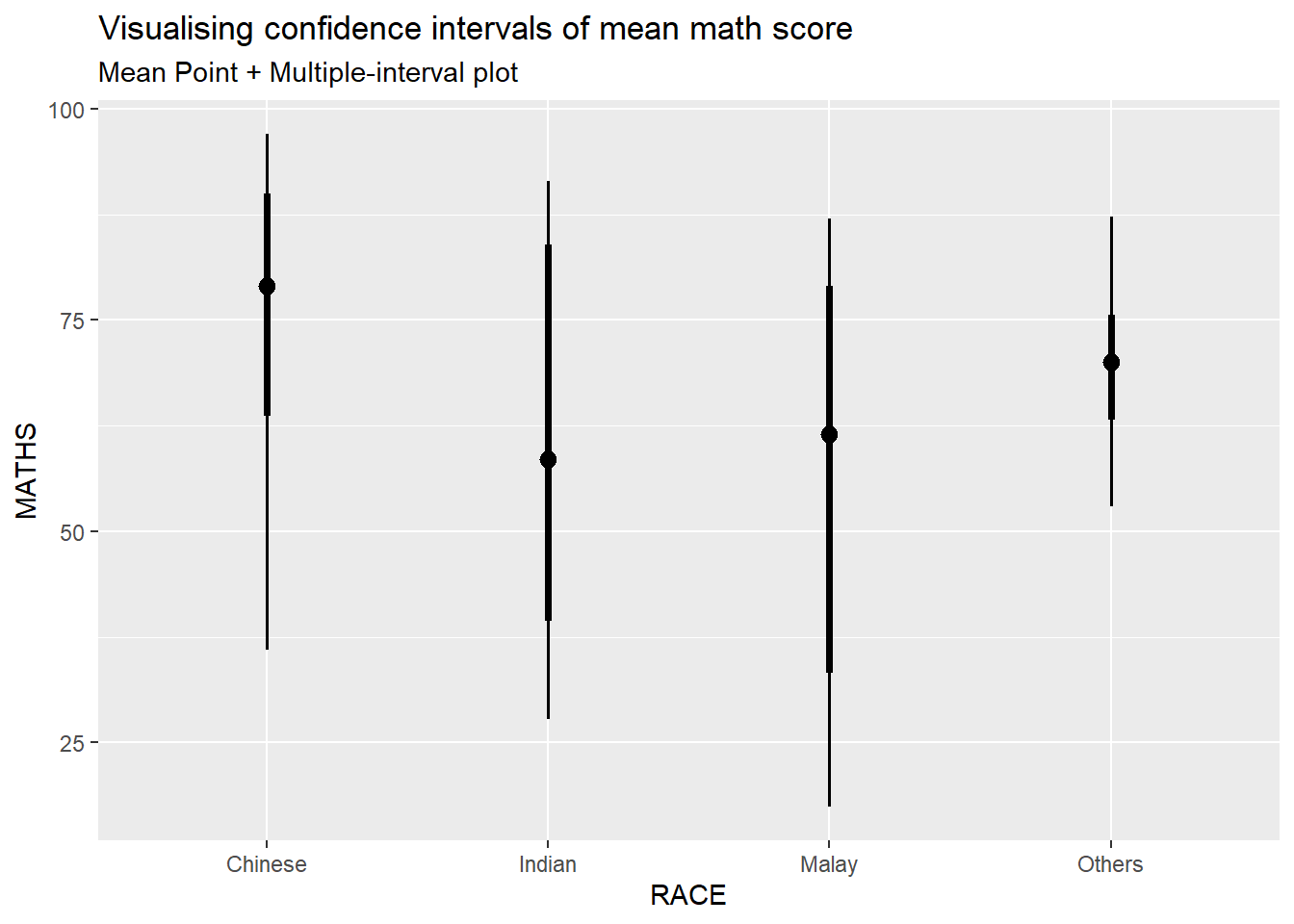
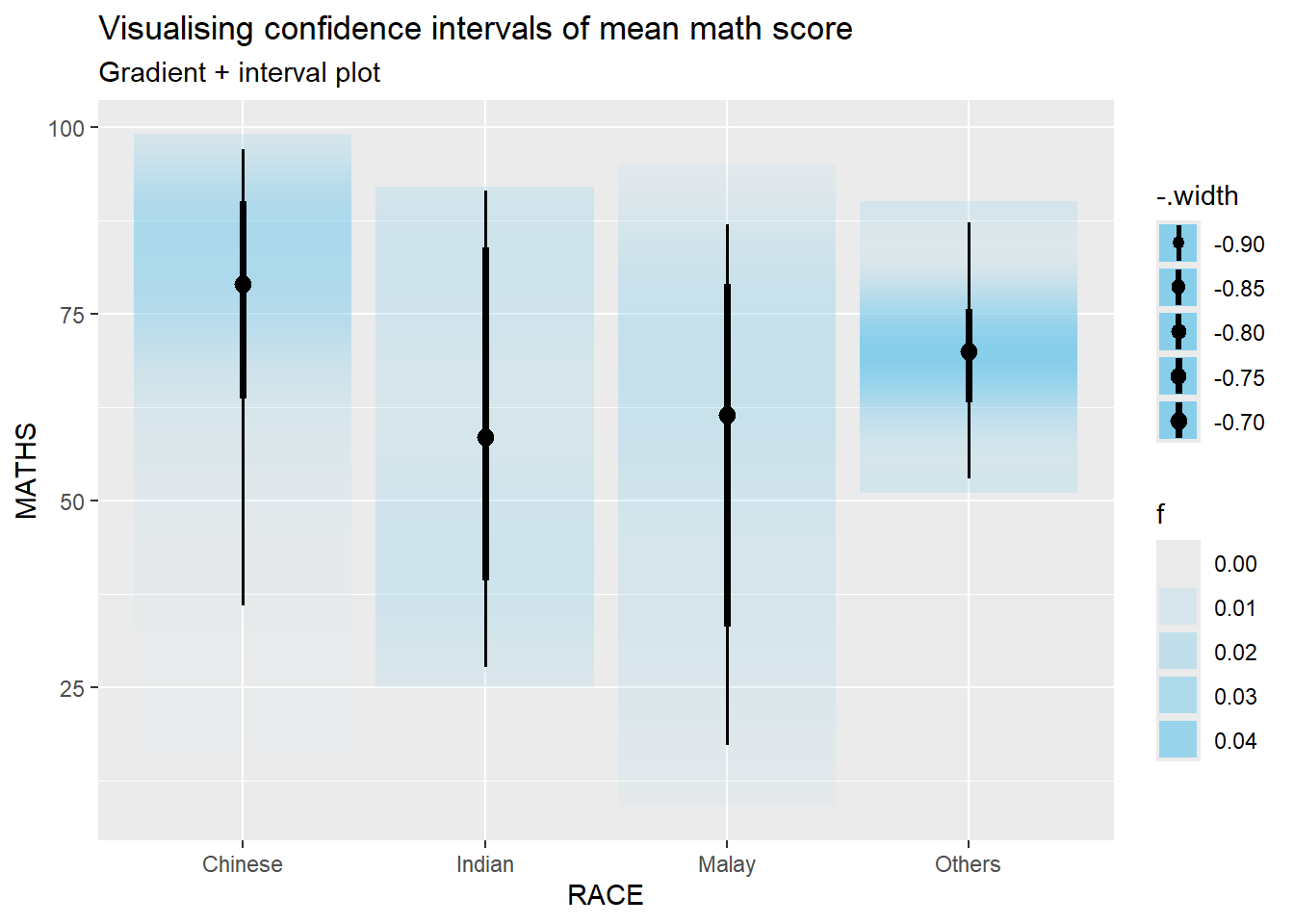
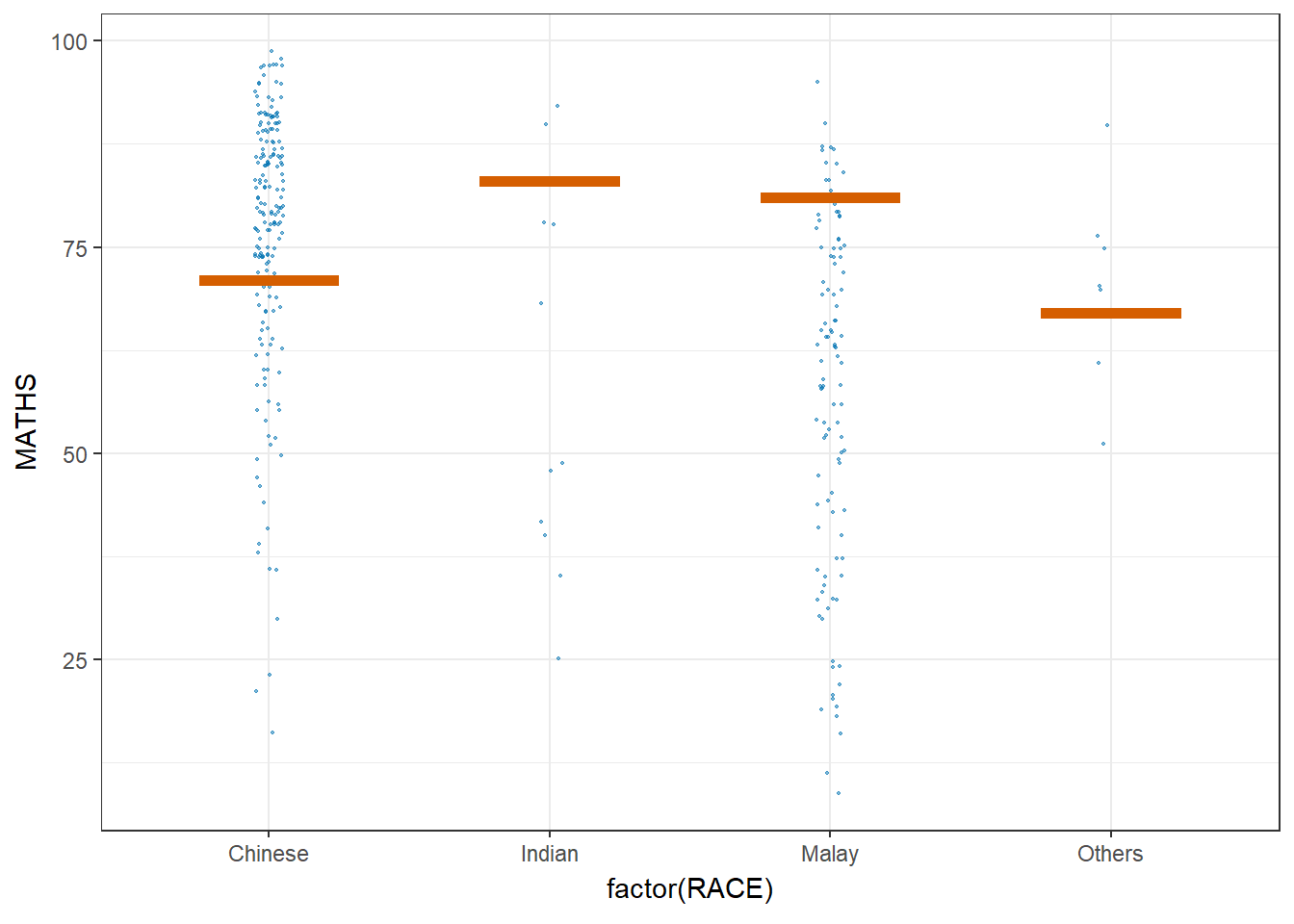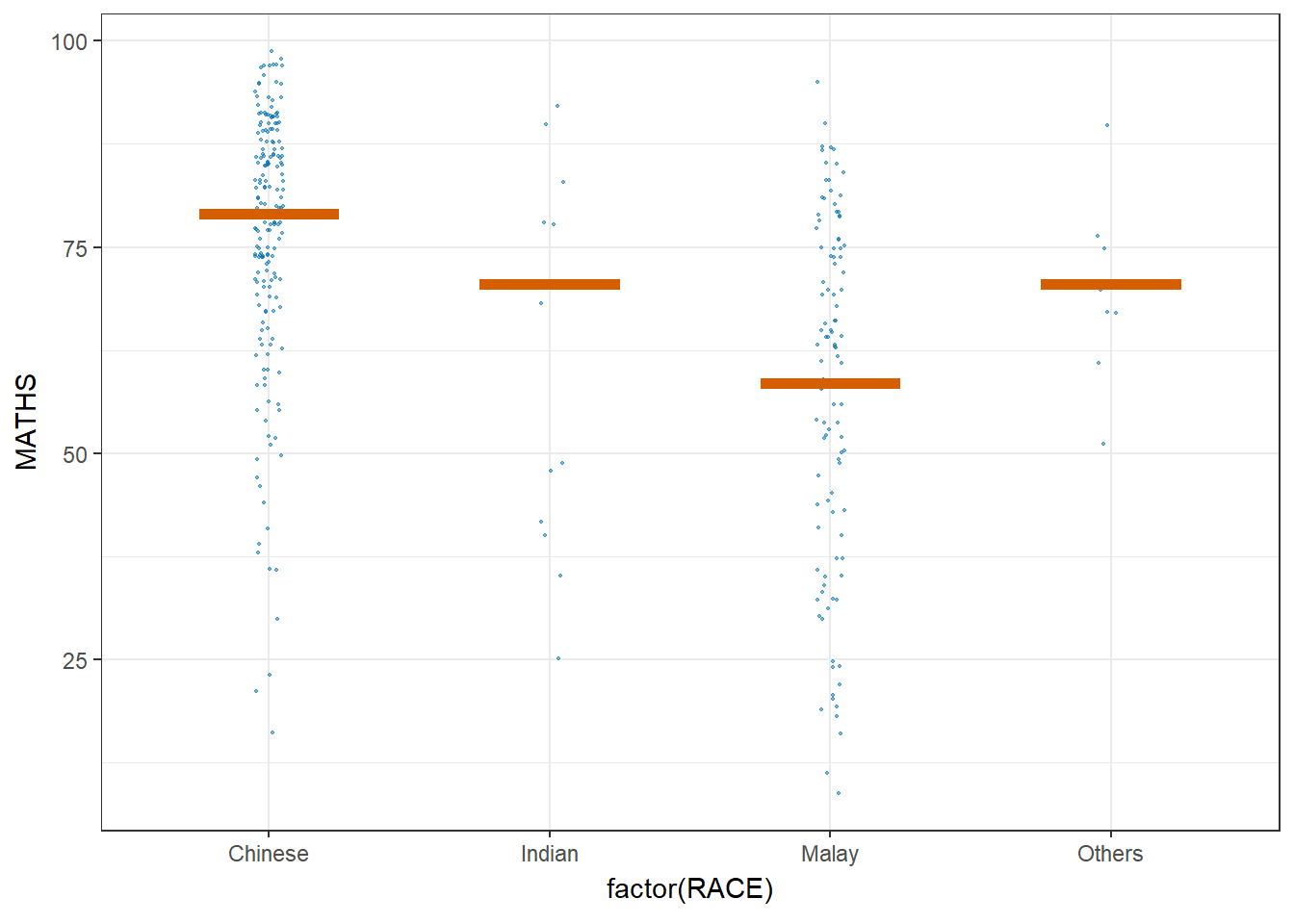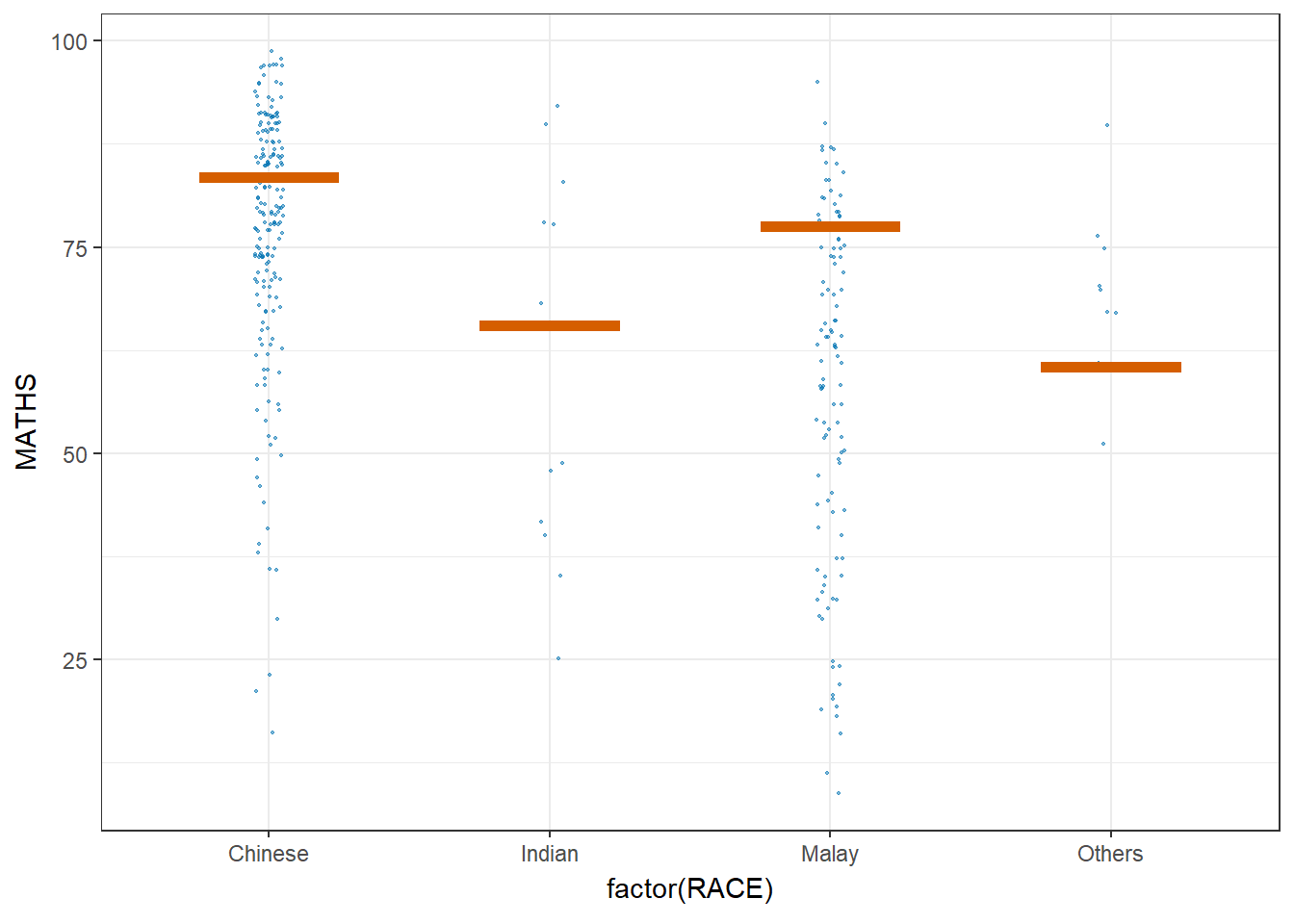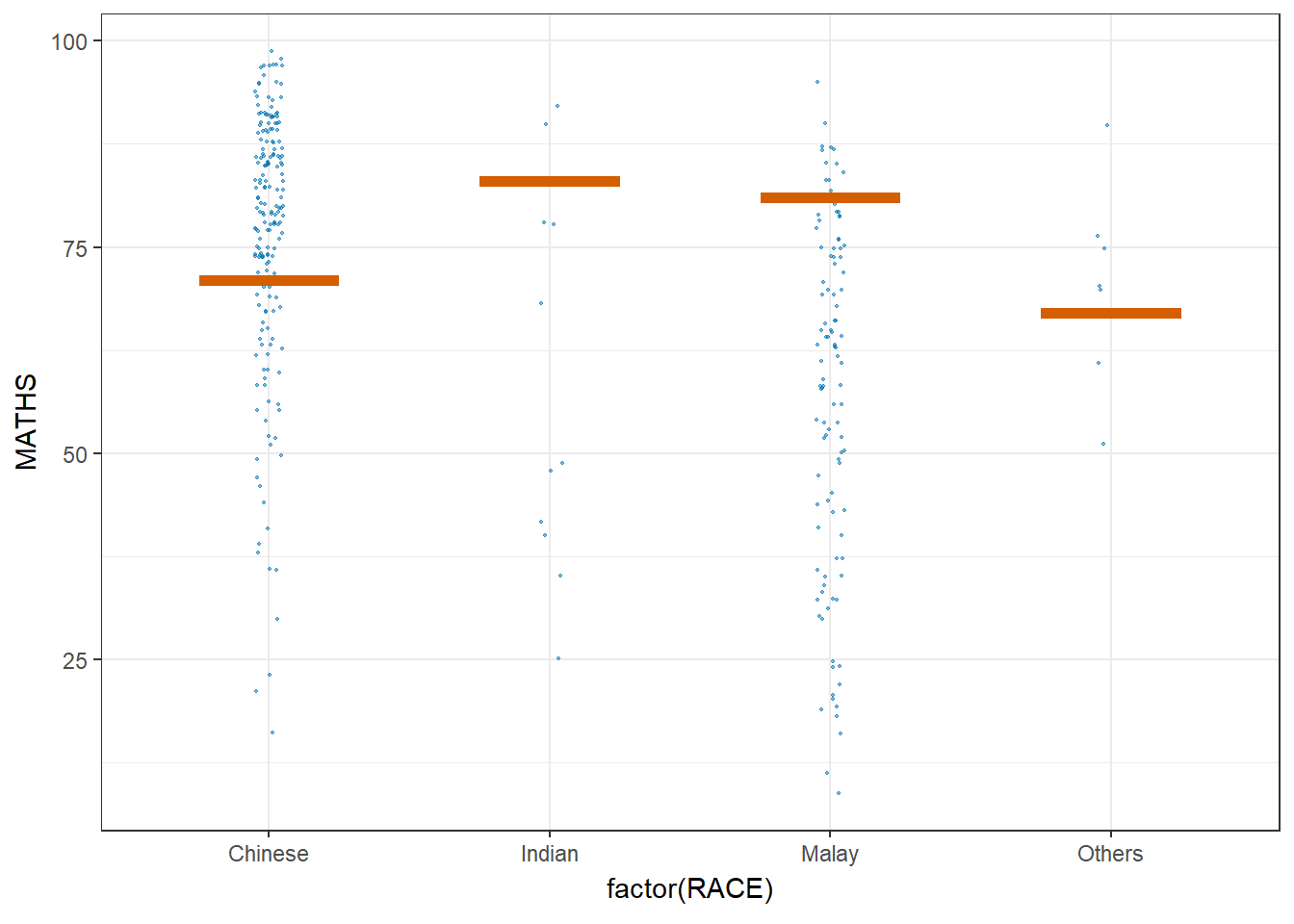
devtools::install_github("wilkelab/ungeviz")strapgod (NA -> ea2b1ecfc...) [GitHub]
rlang (1.1.3 -> 1.1.4 ) [CRAN]
cli (3.6.2 -> 3.6.3 ) [CRAN]
stringi (1.8.3 -> 1.8.4 ) [CRAN]
farver (2.1.1 -> 2.1.2 ) [CRAN]
mvtnorm (1.2-4 -> 1.2-5 ) [CRAN]
rlang (1.1.3 -> 1.1.4) [CRAN]
cli (3.6.2 -> 3.6.3) [CRAN]
stringi (1.8.3 -> 1.8.4) [CRAN]
package 'rlang' successfully unpacked and MD5 sums checked
package 'cli' successfully unpacked and MD5 sums checked
package 'stringi' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\idrin\AppData\Local\Temp\Rtmp2HmPAQ\downloaded_packages
── R CMD build ─────────────────────────────────────────────────────────────────
* checking for file 'C:\Users\idrin\AppData\Local\Temp\Rtmp2HmPAQ\remotes6c3c22a36614\DavisVaughan-strapgod-ea2b1ec/DESCRIPTION' ... OK
* preparing 'strapgod':
* checking DESCRIPTION meta-information ... OK
* checking for LF line-endings in source and make files and shell scripts
* checking for empty or unneeded directories
Omitted 'LazyData' from DESCRIPTION
* building 'strapgod_0.0.4.9000.tar.gz'
package 'rlang' successfully unpacked and MD5 sums checked
package 'cli' successfully unpacked and MD5 sums checked
package 'stringi' successfully unpacked and MD5 sums checked
package 'farver' successfully unpacked and MD5 sums checked
package 'mvtnorm' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\idrin\AppData\Local\Temp\Rtmp2HmPAQ\downloaded_packages
── R CMD build ─────────────────────────────────────────────────────────────────
* checking for file 'C:\Users\idrin\AppData\Local\Temp\Rtmp2HmPAQ\remotes6c3c17373177\wilkelab-ungeviz-aeae12b/DESCRIPTION' ... OK
* preparing 'ungeviz':
* checking DESCRIPTION meta-information ... OK
* checking for LF line-endings in source and make files and shell scripts
* checking for empty or unneeded directories
* building 'ungeviz_0.1.0.tar.gz'
pacman::p_load(ungeviz, plotly, crosstalk,
DT, ggdist, ggridges,
colorspace, gganimate, tidyverse)